




Содержание
Перейти к:
https://doi.org/10.23947/2687-1653-2023-23-3-329-339
Перейти к:
Введение. Экологические проблемы, возникающие на мелководных водоёмах и вызываемые как природными, так и техногенными факторами, ежегодно наносят существенный ущерб аквасистемам и прибрежным территориям. Своевременно определить эти проблемы, а также пути их устранения возможно с использованием современных вычислительных систем. Но проведённые ранее исследования показали, что ресурсов вычислительных систем, использующих только центральный процессор, недостаточно для решения больших научных задач, в частности, по прогнозированию крупных экологических происшествий, оценке нанесенного ими ущерба и определению возможностей их устранения. Для этих целей предлагается использовать модели вычислительной системы и декомпозиции расчётной области для разработки алгоритма параллельноконвейерных вычислений. Целью данной работы является создание модели параллельно-конвейерного вычислительного процесса для решения системы сеточных уравнений модифицированным попеременнотреугольным итерационным методом с использованием декомпозиции трёхмерной равномерной расчётной сетки, учитывающей технические характеристики используемого для расчетов оборудования.
Материалы и методы. Разработаны математические модели вычислительной системы и расчётной сетки. Модель декомпозиции расчётной области выполнена с учётом характеристик гетерогенной системы. Предложен параллельно-конвейерный метод решения системы сеточных уравнений модифицированным попеременнотреугольным итерационным методом.
Результаты исследования. На языке CUDA С написана программа, реализующая параллельно-конвейерный метод решения системы сеточных уравнений модифицированным попеременно-треугольным итерационным методом. Проведённые эксперименты показали, что с увеличением числа потоков время вычислений уменьшается и при декомпозиции расчётной сетки рациональным является разбиение на фрагменты по координате z на величину, не превышающую 10. Результаты экспериментов подтвердили эффективность разработанного параллельно-конвейерного метода.
Обсуждение и заключение. По итогам проведенных исследований разработана модель параллельноконвейерного вычислительного процесса на примере одного из самых трудоёмких этапов решения системы сеточных уравнений модифицированным попеременно-треугольным итерационным методом. Её построение основано на моделях декомпозиции трёхмерной равномерной расчётной сетки, учитывающей технические характеристики используемого в расчетах оборудования. Применение программы позволит ускорить процесс расчёта и равномерно по времени загрузить программные потоки. Проведенные численные эксперименты подтвердили математическую модель декомпозиции расчётной области.
Литвинов В.Н., Руденко Н.Б., Грачева Н.Н. Разработка модели параллельно-конвейерного вычислительного процесса для решения системы сеточных уравнений. Advanced Engineering Research (Rostov-on-Don). 2023;23(3):329-339. https://doi.org/10.23947/2687-1653-2023-23-3-329-339
Litvinov V.N., Rudenko N.B., Gracheva N.N. Model of a Parallel-Pipeline Computational Process for Solving a System of Grid Equations. Advanced Engineering Research (Rostov-on-Don). 2023;23(3):329-339. https://doi.org/10.23947/2687-1653-2023-23-3-329-339
Введение. В последнее время на территории Ростовской области отмечается возникновение ряда серьезных экологических проблем. К ним, в частности, относится эвтрофикация вод Азовского моря и Цимлянского водохранилища, которая вызывает рост вредоносных и токсичных видов популяций фитопланктона [1]. Инженерные работы в акваториях рек и морей приводят к загрязнению прилегающих территорий, изменению популяционной структуры биоты и ухудшению условий воспроизводства ценных и промысловых рыб. Изменение климата на юге России привело к увеличению количества случаев затопления некоторых территорий в районе Таганрогского залива и поймы реки Дон, вызванных сгонно-нагонными явлениями. В последнее десятилетие в летний период несколько раз наблюдалось практически полное осушение русла реки Дон, что приводило к полной остановке судоходства. Чтобы спрогнозировать возникновение и развитие подобных случаев, спланировать пути устранения их последствий, оценить нанесенный ими ущерб, требуются современные программные комплексы, построенные с использованием высокоточных математических моделей, численных методов, алгоритмов и структур данных [2].
В основе математических моделей, используемых при прогнозировании природных и техногенных катастроф, лежат системы дифференциальных уравнений в частных производных, например уравнения Пуассона, Навье-Стокса, диффузии-конвекции-реакции, теплопроводности. Численное решение таких систем приводит к необходимости оперативного хранения больших объёмов данных (в массивах различной структуры) и решения систем сеточных уравнений высокой размерности, превышающих 109. Объём оперативной памяти, требуемой для хранения массивов данных при численном решении только одного уравнения Пуассона для трёхмерной области размерностью 103×103×103 попеременно-треугольным итерационным методом, составляет более 64 Гб. В случае численного решения комбинированных задач требуются сотни гигабайт оперативной памяти, которые могут быть доступны лишь при использовании суперкомпьютерных систем.
Проведенное ранее исследование показало, что ресурсов вычислительной системы, использующей только CPU, недостаточно для решения подобных научных задач [3]. Увеличение мощности и видеопамяти GPU позволило использовать для расчетов ресурсы видеоадаптеров [4]. Эффективность использования GPU зависит от применения параллельных алгоритмов для решения вычислительно-трудоемких задач водной экологии [5–7]. Частично решить проблемы нехватки памяти и вычислительной мощности на рабочих станциях можно установкой дополнительных видеоадаптеров в слоты PCI-E X16 непосредственно и в слоты PCI-E X1 с помощью переходников PCI-E X1–PCI-E X16. Таким образом, количество видеоадаптеров, установленных на одной рабочей станции, можно довести до 12 [8–11].
Всё большую популярность в научном сообществе приобретают гетерогенные вычислительные системы, которые позволяют использовать ресурсы CPU и GPU совместно. Применение таких систем дает возможность уменьшить время расчета научных задач [12–14]. Однако эффективное использование гетерогенной вычислительной среды предполагает модернизацию математических моделей, алгоритмов и программ, их численно реализующих. Гетерогенная система позволяет организовать процесс вычислений в параллельном режиме. При этом должны быть учтены принципиальные различия в построении программных систем, использующих совместно CPU и GPU.
Материалы и методы. Опишем предложенные математические модели вычислительной системы, расчетной сетки, а также метод декомпозиции расчетной области.
Пусть 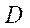 — множество технических характеристик вычислительной системы, тогда:
— множество технических характеристик вычислительной системы, тогда:
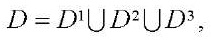 (1)
(1)
где
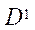 — подмножество характеристик центральных процессоров (CPU) вычислительной системы;
— подмножество характеристик центральных процессоров (CPU) вычислительной системы; 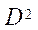 — подмножество характеристик видеоадаптеров (GPU) вычислительной системы;
— подмножество характеристик видеоадаптеров (GPU) вычислительной системы;
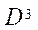 — подмножество характеристик оперативной памяти.
— подмножество характеристик оперативной памяти.
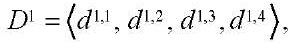 (2)
(2)
где
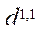 — суммарное число ядер CPU;
— суммарное число ядер CPU;
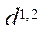 — количество потоков, одновременно обрабатываемых одним ядром процессора CPU;
— количество потоков, одновременно обрабатываемых одним ядром процессора CPU;
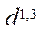 — тактовая частота, МГц;
— тактовая частота, МГц;
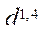 — частота шины центрального процессора, МГц.
— частота шины центрального процессора, МГц.
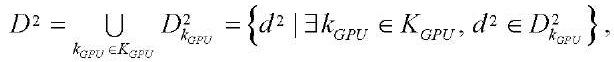 , (3)
, (3)
где
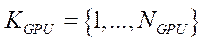 — множество индексов видеоадаптеров;
— множество индексов видеоадаптеров;
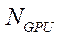 — количество видеоадаптеров вычислительной системы;
— количество видеоадаптеров вычислительной системы;
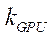 — индекс видеоадаптера.
— индекс видеоадаптера.
Каждый видеоадаптер представим в виде кортежа:
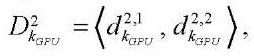 , (4)
, (4)
где
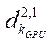 — объём видеопамяти видеоадаптера с индексом
— объём видеопамяти видеоадаптера с индексом 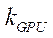 , Гб;
, Гб;
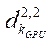 — количество потоковых мультипроцессоров.
— количество потоковых мультипроцессоров.
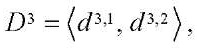 , (5)
, (5)
где
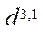 — суммарный объём оперативной памяти, Гб;
— суммарный объём оперативной памяти, Гб;
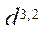 — тактовая частота оперативной памяти, МГц.
— тактовая частота оперативной памяти, МГц.
Пусть 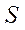 — множество программных потоков, задействованных в вычислительном процессе, тогда:
— множество программных потоков, задействованных в вычислительном процессе, тогда:
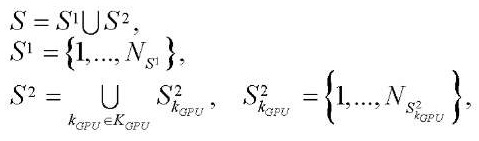 (6)
(6)
где
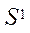 — подмножество программных потоков, реализующих процесс расчета на CPU;
— подмножество программных потоков, реализующих процесс расчета на CPU;
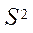 — подмножество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU;
— подмножество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU;
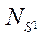 — количество задействованных программных потоков CPU;
— количество задействованных программных потоков CPU;
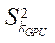 — подмножество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU с индексом
— подмножество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU с индексом 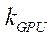 ;
;
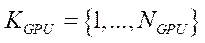 — множество индексов GPU;
— множество индексов GPU;
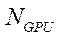 — количество GPU в вычислительной системе;
— количество GPU в вычислительной системе;
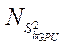 — количество задействованных потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU с индексом
— количество задействованных потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU с индексом 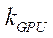 .
.
Пусть 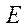 — множество идентификаторов программных потоков. Тогда для идентификации программных потоков в вычислительной системе каждому элементу множества программных потоков S поставим в соответствие кортеж
— множество идентификаторов программных потоков. Тогда для идентификации программных потоков в вычислительной системе каждому элементу множества программных потоков S поставим в соответствие кортеж 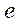 из двух элементов:
из двух элементов:
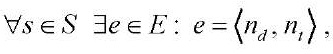 , (7)
, (7)
где
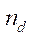 — индекс вычислительного устройства в вычислительной системе;
— индекс вычислительного устройства в вычислительной системе;
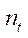 — индекс программного потока CPU или потокового блока GPU.
— индекс программного потока CPU или потокового блока GPU.
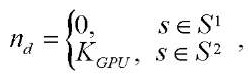 , (8)
, (8)
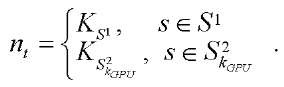 . (9)
. (9)
Возьмём расчётную область со следующими параметрами:
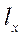 — характерный размер по оси
— характерный размер по оси 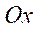 ;
;
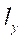 — по оси
— по оси 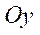 ;
; 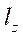 — по оси
— по оси 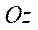 .
.
Сопоставим с указанной областью равномерную расчётную сетку следующего вида:
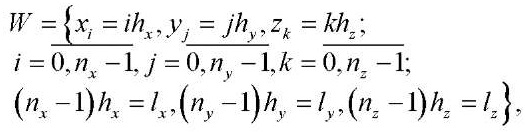 (10)
(10)
где
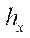 ,
, 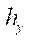 ,
, 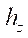 — шаги расчётной сетки по соответствующим пространственным направлениям;
— шаги расчётной сетки по соответствующим пространственным направлениям;
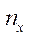 ,
, 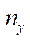 ,
, 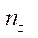 — количество узлов расчётной сетки по соответствующим пространственным направлениям.
— количество узлов расчётной сетки по соответствующим пространственным направлениям.
Тогда множество узлов расчётной сетки представим в виде:
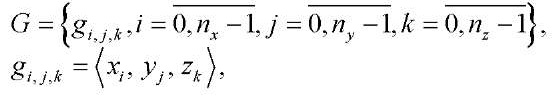 (11)
(11)
где
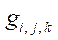 — узел расчётной сетки.
— узел расчётной сетки.
Число узлов расчётной сетки 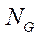 вычисляется по формуле:
вычисляется по формуле:
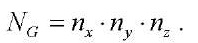 . (12)
. (12)
Под подразделом расчётной сетки 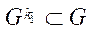 (далее — подраздел) будем понимать подмножество узлов расчётной сетки
(далее — подраздел) будем понимать подмножество узлов расчётной сетки  .
.
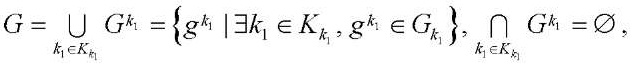 , (13)
, (13)
где
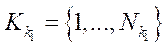 — множество индексов подразделов
— множество индексов подразделов 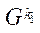 расчётной сетки
расчётной сетки 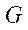 ;
;
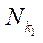 — количество подразделов
— количество подразделов 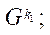
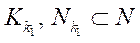 ;
;
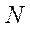 — множество натуральных чисел;
— множество натуральных чисел;
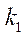 — индекс подраздела
— индекс подраздела 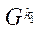 .
.
Так как 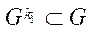 , тогда:
, тогда:
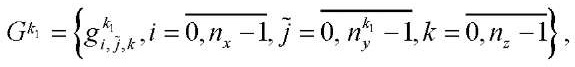 , (14)
, (14)
где
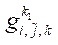 — узел подраздела
— узел подраздела 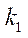 ;
;
знак 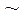 обозначает принадлежность к подразделу;
обозначает принадлежность к подразделу;
![]() — индекс узла подраздела
— индекс узла подраздела 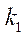 по координате
по координате 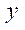 ;
;
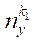 — количество узлов в подразделе
— количество узлов в подразделе 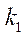 по координате
по координате 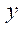 .
.
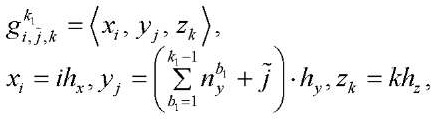 (15)
(15)
где
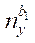 — количество узлов по координате
— количество узлов по координате 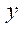
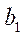 -го раздела.
-го раздела.
Под блоком расчётной сетки 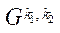 (далее — блок) будем понимать подмножество узлов расчётной сетки подраздела
(далее — блок) будем понимать подмножество узлов расчётной сетки подраздела 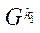 .
.
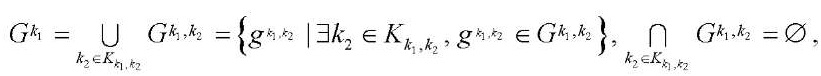 , (16)
, (16)
где
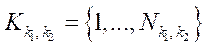 — множество индексов блоков
— множество индексов блоков 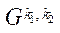 подраздела
подраздела 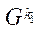 ;
;
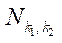 — количество блоков
— количество блоков 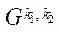 ;
;
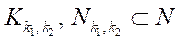 ;
;
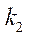 — индекс блока
— индекс блока 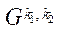 подраздела
подраздела 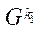 .
.
Так как 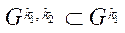 , тогда:
, тогда:
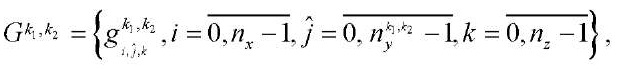 , (17)
, (17)
где
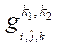 — узел блока
— узел блока 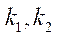 ;
;
знак 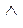 обозначает принадлежность к блоку;
обозначает принадлежность к блоку;
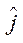 — индекс узла блока
— индекс узла блока 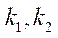 по координате
по координате 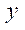 ;
;
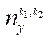 — количество узлов в блоке
— количество узлов в блоке 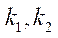 по координате
по координате 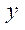 .
.
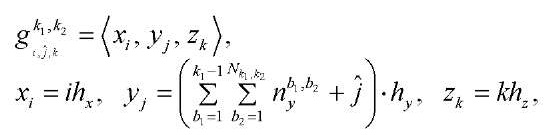 (18)
(18)
где
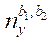 — количество узлов блока
— количество узлов блока 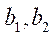 .
.
Под фрагментом расчётной сетки 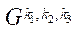 (далее — фрагмент) будем понимать подмножество узлов расчётной сетки блока
(далее — фрагмент) будем понимать подмножество узлов расчётной сетки блока 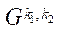 подраздела
подраздела 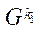 .
.
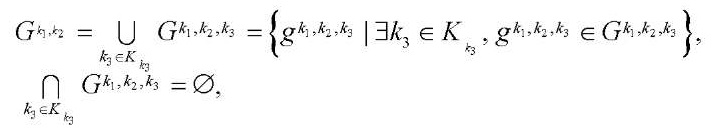 (19)
(19)
где
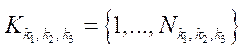 — множество индексов фрагментов
— множество индексов фрагментов 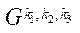 блока
блока 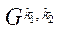 подраздела
подраздела 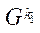 ;
;
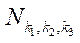 — количество фрагментов
— количество фрагментов 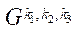 ;
;
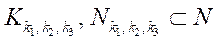 ;
;
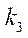 — индекс фрагмента
— индекс фрагмента 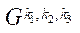 блока
блока 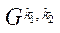 подраздела
подраздела 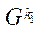 .
.
Каждому индексу 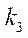 фрагмента
фрагмента 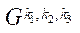 поставим в соответствие кортеж индексов
поставим в соответствие кортеж индексов 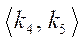 , предназначенный для хранения координат фрагмента в плоскости
, предназначенный для хранения координат фрагмента в плоскости 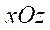 , где
, где 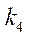 — индекс фрагмента по координате
— индекс фрагмента по координате 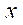 ;
; 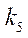 — индекс фрагмента по координате
— индекс фрагмента по координате 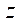 .
.
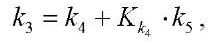 , (20)
, (20)
где
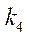 — индекс фрагмента по координате
— индекс фрагмента по координате 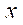 ;
;
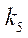 – индекс фрагмента по координате
– индекс фрагмента по координате 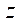 .
.
Количество фрагментов 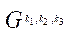 блока
блока 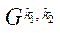 вычислим по формуле:
вычислим по формуле:
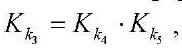 , (21)
, (21)
где
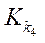 — количество фрагментов по оси
— количество фрагментов по оси 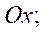
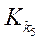 — количество фрагментов по координате
— количество фрагментов по координате 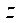 .
.
Так как 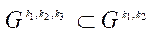 , тогда:
, тогда:
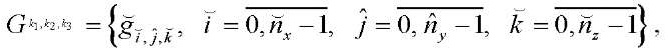 , (22)
, (22)
где
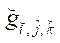 — узел фрагмента;
— узел фрагмента;
знак ‿ обозначает принадлежность к фрагменту;
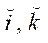 — индексы узла фрагмента по координатам
— индексы узла фрагмента по координатам 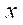 ,
, 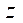 ;
;
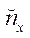 ,
, 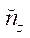 — количество узлов расчётной сетки в фрагменте по координатам
— количество узлов расчётной сетки в фрагменте по координатам 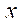 ,
, 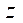 ;
;
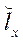 ,
, 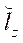 — размеры фрагмента по координатам
— размеры фрагмента по координатам 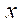 ,
, 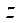 .
.
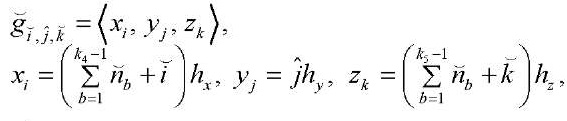 (23)
(23)
где 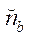 — количество узлов
— количество узлов  -го фрагмента.
-го фрагмента.
Введем множество сопоставлений блоков расчётной сетки программным потокам 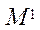
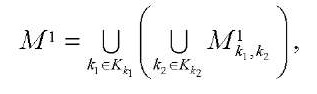 , (24)
, (24)
где 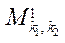 — элемент множества
— элемент множества 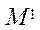 .
.
Пусть 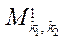 — сопоставление блока
— сопоставление блока 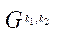 программному потоку
программному потоку 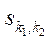 , тогда:
, тогда:
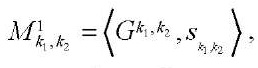 , (25)
, (25)
где 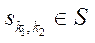 — программный поток, вычисляющий блок
— программный поток, вычисляющий блок 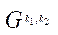 .
.
В процессе решения задач гидродинамики на трехмерных расчетных сетках большой размерности необходимы высокопроизводительные вычислительные системы и огромные объемы памяти для хранения данных. Ресурсов одного вычислительного устройства недостаточно для вычислений и хранения трехмерной расчетной сетки со всеми ее данными. Для решения этой проблемы предложены различные способы декомпозиции расчетных сеток с последующим применением параллельных алгоритмов расчета в гетерогенных вычислительных средах [15].
Для декомпозиции расчётной сетки необходимо учитывать производительность вычислительных устройств, участвующих в расчётах. Под производительностью будем понимать количество узлов расчётной сетки, рассчитываемых с помощью заданного алгоритма в единицу времени.
Предположим, что все вычислительные устройства используются для расчётов. Тогда суммарная производительность вычислительной системы 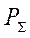 вычисляется по формуле:
вычисляется по формуле:
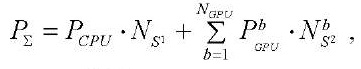 , (26)
, (26)
где
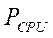 — производительность одного потока CPU;
— производительность одного потока CPU;
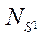 — число программных потоков, реализующих процесс расчета на CPU;
— число программных потоков, реализующих процесс расчета на CPU;
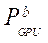 — производительность GPU с индексом
— производительность GPU с индексом 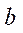 на одном потоковом мультипроцессоре;
на одном потоковом мультипроцессоре;
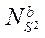 — количество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU.
— количество потоковых блоков CUDA, реализующих процесс расчета на потоковых мультипроцессорах GPU.
Тогда рассчитать количество узлов расчётной сетки 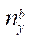 в подразделе по координате
в подразделе по координате 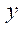 для каждого GPU с индексом
для каждого GPU с индексом 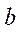 можно по формуле:
можно по формуле:
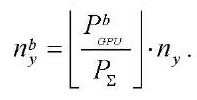 . (27)
. (27)
В процессе вычисления по формуле (27) получим остаток — некоторое количество узлов расчётной сетки. Эти узлы будут располагаться в оперативной памяти. Количество оставшихся узлов 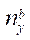 по координате
по координате 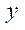 рассчитывается по формуле:
рассчитывается по формуле:
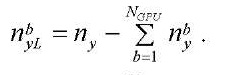 . (28)
. (28)
Для вычисления количества узлов по координате 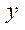 в блоках расчётной сетки, обрабатываемых потоковыми мультипроцессорами GPU, воспользуемся формулами:
в блоках расчётной сетки, обрабатываемых потоковыми мультипроцессорами GPU, воспользуемся формулами:
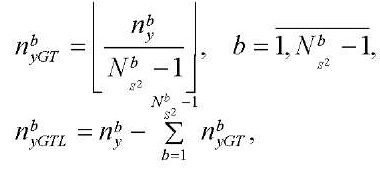 (29)
(29)
где 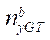 — количество узлов по координате
— количество узлов по координате 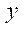 в блоках расчётной сетки, обрабатываемых потоковыми мультипроцессорами GPU с индексом
в блоках расчётной сетки, обрабатываемых потоковыми мультипроцессорами GPU с индексом 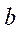 , кроме последнего блока;
, кроме последнего блока;
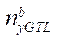 — количество узлов по координате
— количество узлов по координате 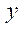 в последнем блоке расчётной сетки, обрабатываемом потоковыми мультипроцессорами GPU с индексом
в последнем блоке расчётной сетки, обрабатываемом потоковыми мультипроцессорами GPU с индексом 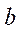 .
.
Для вычисления количества узлов расчётной сетки по координате в блоках, обрабатываемых программными потоками, реализующими процесс расчета на CPU, воспользуемся формулами:
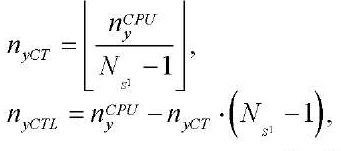 (30)
(30)
где
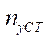 — количество узлов расчётной сетки по координате
— количество узлов расчётной сетки по координате 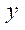 , обрабатываемых программными потоками CPU, кроме последнего потока;
, обрабатываемых программными потоками CPU, кроме последнего потока;
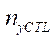 — количество узлов расчётной сетки по координате
— количество узлов расчётной сетки по координате 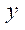 , обрабатываемых программными потоками CPU, в последнем потоке.
, обрабатываемых программными потоками CPU, в последнем потоке.
Рассчитаем количество фрагментов расчётной сетки по координате 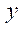 :
:
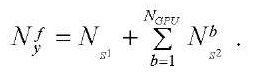 . (31)
. (31)
Пусть задано количество фрагментов 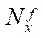 и
и 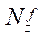 по координатам
по координатам 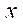 и
и 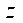 соответственно. Тогда количество узлов расчётной сетки по координате
соответственно. Тогда количество узлов расчётной сетки по координате 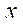 вычисляется по формулам:
вычисляется по формулам:
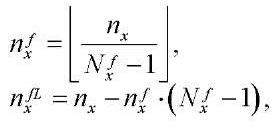 (32)
(32)
где
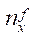 — количество узлов расчётной сетки по координате
— количество узлов расчётной сетки по координате 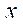 во всех фрагментах, кроме последнего;
во всех фрагментах, кроме последнего;
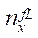 — количество узлов расчётной сетки по координате
— количество узлов расчётной сетки по координате 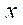 в последнем фрагменте.
в последнем фрагменте.
Аналогично вычисляется количество узлов расчётной сетки по координате 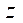 :
:
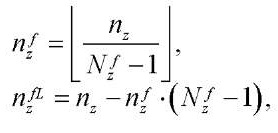 (33)
(33)
где
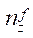 — количество узлов расчётной сетки по координате z во всех фрагментах, кроме последнего;
— количество узлов расчётной сетки по координате z во всех фрагментах, кроме последнего;
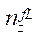 — количество узлов расчётной сетки по координате
— количество узлов расчётной сетки по координате 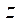 в последнем фрагменте.
в последнем фрагменте.
Опишем модель параллельно-конвейерного метода. Пусть на 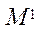 необходимо организовать параллельный процесс вычислений некоторой функции
необходимо организовать параллельный процесс вычислений некоторой функции 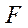 , причем вычисления в каждом фрагменте
, причем вычисления в каждом фрагменте 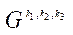 зависят от значений в соседних фрагментах, каждый из которых имеет хотя бы один из индексов по координатам
зависят от значений в соседних фрагментах, каждый из которых имеет хотя бы один из индексов по координатам 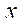 ,
, 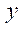 и
и 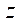 на единицу меньший, чем у текущего (рис. 1).
на единицу меньший, чем у текущего (рис. 1).
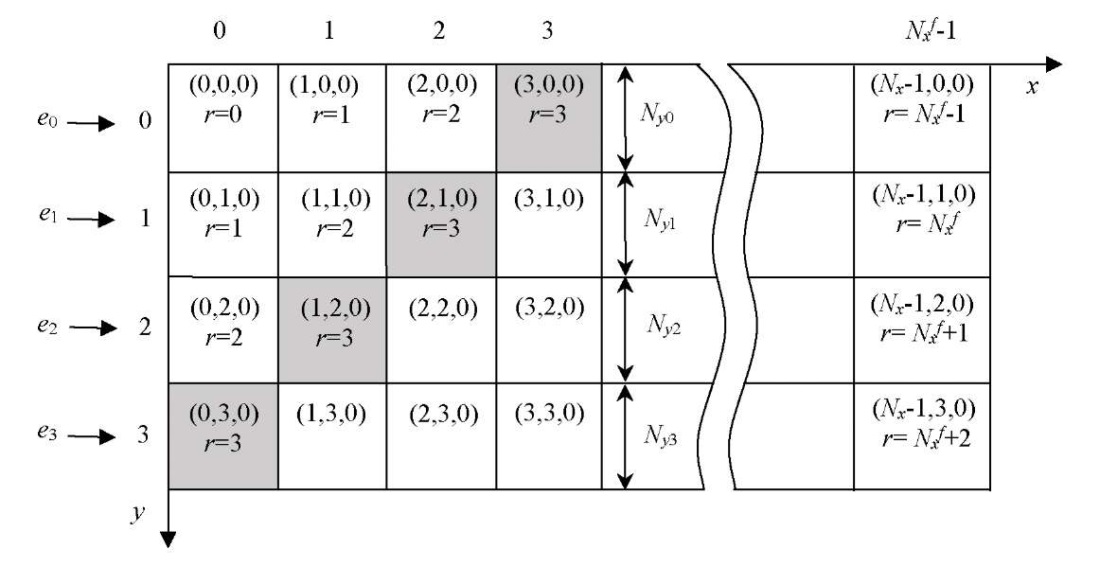
Рис. 1. Параллельно-конвейерный вычислительный процесс
Для организации параллельно-конвейерного метода введём множество кортежей  задающих соответствия
задающих соответствия  между идентификаторами программных потоков
между идентификаторами программных потоков  , обрабатывающих фрагменты
, обрабатывающих фрагменты 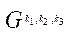 , номерам шагов параллельно-конвейерного метода
, номерам шагов параллельно-конвейерного метода 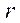 :
:
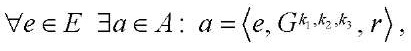 , (34)
, (34)
где
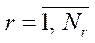 — номер шага параллельно-конвейерного метода;
— номер шага параллельно-конвейерного метода;
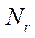 — число шагов параллельно-конвейерного метода, вычисляемое по формуле:
— число шагов параллельно-конвейерного метода, вычисляемое по формуле:
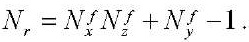 . (35)
. (35)
Полная загрузка всех вычислителей в предлагаемом параллельно-конвейерном методе начинается с шага 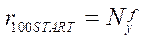 и заканчивается на шаге
и заканчивается на шаге 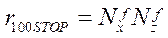 . При этом общее количество шагов с полной загрузкой вычислителей
. При этом общее количество шагов с полной загрузкой вычислителей 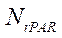 составит:
составит:
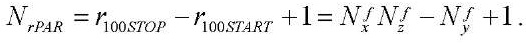 . (36)
. (36)
Время вычислений некоторой функции 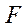 параллельно-конвейерным методом запишем в виде:
параллельно-конвейерным методом запишем в виде:
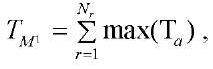 , (37)
, (37)
где 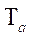 — вектор значений затрат времени на обработку фрагментов в параллельном режиме.
— вектор значений затрат времени на обработку фрагментов в параллельном режиме.
Результаты исследования. Вычислительные эксперименты проводились на высокопроизводительной вычислительной системе К-60 Института прикладной математики им. М. В. Келдыша Российской академии наук. Использовалась секция с GPU, каждый узел которой оснащён двумя процессорами Intel Xeon Gold 6142 v4, четырьмя видеоадаптерами Nvidia Volta GV100GL и 768 Гб оперативной памяти.
Вычислительный эксперимент состоял из двух этапов — подготовительного и основного. На подготовительном этапе проверялась корректность декомпозиции расчетной области на подразделы, блоки и фрагменты путем поэлементного сравнения значений в узлах исходной сетки и в фрагментах, полученных в результате декомпозиции. Затем проверялась работа алгоритма управления потоками, в процессе которого фиксировалось время, затрачиваемое на расчет 1, 8, 16 и 32 фрагментов расчетной сетки размерностью 50 узлов по пространственным координатам 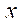 ,
, 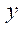 и
и 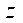 тем же количеством потоков CPU
тем же количеством потоков CPU 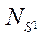 итерационным попеременно-треугольным методом в параллельном режиме. Выполнялось 10 повторов с вычислением среднего арифметического
итерационным попеременно-треугольным методом в параллельном режиме. Выполнялось 10 повторов с вычислением среднего арифметического 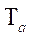 и стандартного отклонения s. По полученным данным вычислялось время
и стандартного отклонения s. По полученным данным вычислялось время 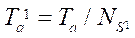 , затрачиваемое каждым потоком на обработку одного фрагмента расчетной сетки и ускорение
, затрачиваемое каждым потоком на обработку одного фрагмента расчетной сетки и ускорение 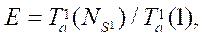 равное отношению времени
равное отношению времени 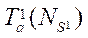 обработки одного фрагмента
обработки одного фрагмента 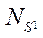 потоками к соответствующему времени обработки одним потоком
потоками к соответствующему времени обработки одним потоком 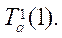 Экспериментальные данные приведены в таблице 1. Проведённый эксперимент показал, что стандартное отклонение имеет наименьшее значение в случае использования 32 параллельных потоков CPU и составляет 0,026 мс, то есть использование 32 параллельных потоков CPU при расчёте 32 фрагментов расчётной сетки даёт более равномерную по времени загруженность программных потоков, что в целом повышает эффективность работы вычислительного узла. При этом среднее значение расчета одного фрагмента составило 4,14 мс. Зависимость ускорения
Экспериментальные данные приведены в таблице 1. Проведённый эксперимент показал, что стандартное отклонение имеет наименьшее значение в случае использования 32 параллельных потоков CPU и составляет 0,026 мс, то есть использование 32 параллельных потоков CPU при расчёте 32 фрагментов расчётной сетки даёт более равномерную по времени загруженность программных потоков, что в целом повышает эффективность работы вычислительного узла. При этом среднее значение расчета одного фрагмента составило 4,14 мс. Зависимость ускорения  от числа потоков получилась линейная
от числа потоков получилась линейная 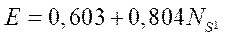 , с коэффициентом детерминации, равным 0,99. Получили, что с увеличением числа потоков ускорение разработанного алгоритма возрастает. Это свидетельствует об эффективном использовании подсистемы при работе с памятью.
, с коэффициентом детерминации, равным 0,99. Получили, что с увеличением числа потоков ускорение разработанного алгоритма возрастает. Это свидетельствует об эффективном использовании подсистемы при работе с памятью.
Таблица 1
Результаты подготовительного этапа вычислительного эксперимента

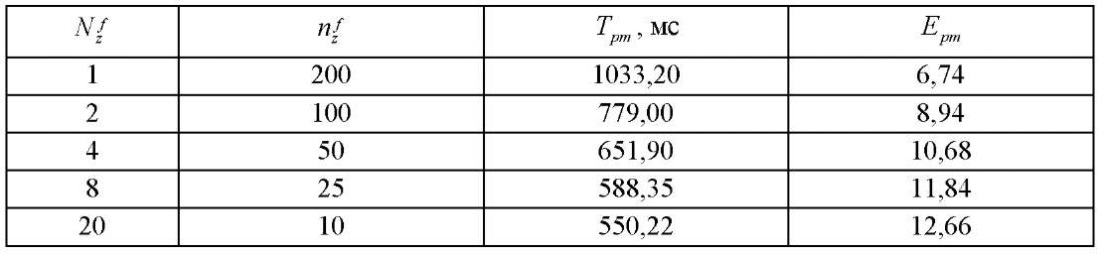
На основном этапе вычислительного эксперимента трёхмерная расчетная область, имеющая размеры 1600, 1600, 200 по пространственным координатам 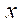 ,
, 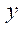 и
и 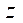 соответственно, разбивалась на 32 фрагмента по 50 узлов по каждой из координат
соответственно, разбивалась на 32 фрагмента по 50 узлов по каждой из координат 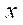 и
и 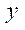 . Разбиение на фрагменты по координате
. Разбиение на фрагменты по координате 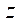 приведено в таблице 2. Для каждого варианта декомпозиции с десятикратной повторностью замерялось время обработки всей расчетной сетки предлагаемым параллельно-конвейерным методом и вычислялось его среднее значение
приведено в таблице 2. Для каждого варианта декомпозиции с десятикратной повторностью замерялось время обработки всей расчетной сетки предлагаемым параллельно-конвейерным методом и вычислялось его среднее значение 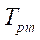 . Ускорение
. Ускорение 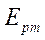 вычислялось как отношение
вычислялось как отношение 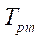 ко времени
ко времени 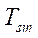 расчета последовательной версией алгоритма, равному 6963 мс. Получено уравнение регрессии
расчета последовательной версией алгоритма, равному 6963 мс. Получено уравнение регрессии 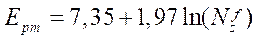 с коэффициентом детерминации, равным 0,94. Анализ результатов основного этапа вычислительного эксперимента показал существенное замедление роста
с коэффициентом детерминации, равным 0,94. Анализ результатов основного этапа вычислительного эксперимента показал существенное замедление роста 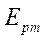 при
при 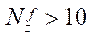 . Поэтому делаем вывод о том, что оптимальным является разбиение на фрагменты по координате
. Поэтому делаем вывод о том, что оптимальным является разбиение на фрагменты по координате 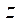 на величину, не превышающую 10.
на величину, не превышающую 10.
Таблица 2
Результаты основного этапа вычислительного эксперимента
Обсуждение и заключение. В результате проведённых исследований разработана модель параллельно-конвейерного вычислительного процесса на примере одного из самых трудоёмких этапов решения системы сеточных уравнений модифицированным попеременно-треугольным итерационным методом. Её построение основано на моделях декомпозиции трёхмерной равномерной расчётной сетки, учитывающей технические характеристики используемого в расчетах оборудования.
Результаты, полученные в ходе вычислительных экспериментов, подтверждают эффективность разработанного метода. Подтверждена и корректность декомпозиции расчетной области на подразделы, блоки и фрагменты. Проверена работа алгоритма управления потоками, при этом выявлено, что стандартное отклонение имеет наименьшее значение в случае использования 32 параллельных потоков CPU и составляет 0,026 мс, то есть использование 32 параллельных потоков CPU при расчёте 32 фрагментов расчётной сетки даёт более равномерную по времени загруженность программных потоков. При этом среднее значение расчета одного фрагмента составило 4,14 мс.
Результаты обработки замеров времени расчетов предлагаемым параллельно-конвейерным методом показали существенное замедление роста ускорения при разбиении на фрагменты по координате 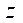 при
при 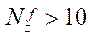 . Получили, что оптимальным является разбиение на фрагменты по координате
. Получили, что оптимальным является разбиение на фрагменты по координате 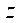 на величину, не превышающую 10.
на величину, не превышающую 10.
1. Shiganova T.A., Alekseenko E., Kazmin A.S. Predicting Range Expansion of Invasive Ctenophore Mnemiopsis leidyi A. Agassiz 1865 under Current Environmental Conditions and Future Climate Change Scenarios. Estuarine, Coastal and Shelf Science. 2019;227:106347. https://doi.org/10.1016/j.ecss.2019.106347
2. Sukhinov A.I., Chistyakov A.E., Nikitina A.V., Filina A.A., Lyashchenko T.V., Litvinov V.N. The Use of Supercomputer Technologies for Predictive Modeling of Pollutant Transport in Boundary Layers of the Atmosphere and Water Bodies. In book: L. Sokolinsky, M. Zymbler (eds). Parallel Computational Technologies. Cham: Springer; 2019. P. 225–241. https://doi.org/10.1007/978-3-030-28163-2_16
3. Rodriguez D., Gomez D., Alvarez D., Rivera S. A Review of Parallel Heterogeneous Computing Algorithms in Power Systems. Algorithms. 2021;14(10):275. https://doi.org/10.3390/a14100275
4. Osman A.M. Abdelrahman. GPU Computing Taxonomy. In ebook: Wen-Jyi Hwang (ed). Recent Progress in Parallel and Distributed Computing. London: InTech; 2017. https://doi.org/10.5772/intechopen.68179
5. Parker A. GPU Computing: The Future of Computing. In: Proceedings of the West Virginia Academy of Science Morgantown, WV: WVAS; 2018. Vol. 90 (1). https://doi.org/10.55632/pwvas.v90i1.393
6. Nakano Koji. Theoretical Parallel Computing Models for GPU Computing. In book: Koç Ç. (ed). Open Problems in Mathematics and Computational Science. Cham: Springer; 2014 . P. 341–359. https://doi.org/10.1007/978-3-319-10683-0_14
7. Bhargavi K., Sathish Babu B. GPU Computation and Platforms. In book: Ganesh Chandra Deka (ed). Emerging Research Surrounding Power Consumption and Performance Issues in Utility Computing. Hershey, PA: IGI Global; 2016. P. 136–174. 10.4018/978-1-4666-8853-7.ch007
8. Ebrahim Zarei Zefreh, Leili Mohammad Khanli, Shahriar Lotfi, Jaber Karimpour. 3 D Data Partitioning for 3 Level Perfectly Nested Loops on Heterogeneous Distributed System. Concurrency and Computation: Practice and Experience. 2017;29(5):e3976. 10.1002/cpe.3976
9. Fan Yang, Tongnian Shi, Han Chu, Kun Wang. The Design and Implementation of Parallel Algorithm Accelerator Based on CPU-GPU Collaborative Computing Environment. Advanced Materials Research. 2012;529:408–412. 10.4028/www.scientific.net/AMR.529.408
10. Varshini Subhash, Karran Pandey, Vijay Natarajan. A GPU Parallel Algorithm for Computing Morse-Smale Complexes. IEEE Transactions on Visualization and Computer Graphics. 2022. P. 1–15. 10.1109/TVCG.2022.3174769
11. Leiming Yu., Fanny Nina-Paravecino, David R. Kaeli, Qianqian Fang. Scalable and Massively Parallel Monte Carlo Photon Transport Simulations for Heterogeneous Computing Platforms. Journal of Biomedical Optics. 2018;23(1):010504. 10.1117/1.JBO.23.1.010504
12. Fujimoto R.M. Research Challenges in Parallel and Distributed Simulation. ACM Transactions on Modeling and Computer Simulation. 2016;26(4):1–29. 10.1145/2866577
13. Qiang Qin, ChangZhen Hu, TianBao Ma. Study on Complicated Solid Modeling and Cartesian Grid Generation Method. Science China Technological Sciences. 2014;57:630–636. 10.1007/s11431-014-5485-5
14. Seyong Lee, Jeffrey Vetter. Moving Heterogeneous GPU Computing into the Mainstream with Directive-Based, High-Level Programming Models. In: Proc. DOE Exascale Research Conference. Portland, Or; 2012.
15. Thoman P., Dichev K., Heller Th., Iakymchuk R., Aguilar X., Hasanov Kh., et al. A Taxonomy of Task-Based Parallel Programming Technologies for High-Performance Computing. Journal of Supercomputing. 2018;74(2):1422– 1434. 10.1007/s11227-018-2238-4
Владимир Николаевич Литвинов, кандидат технических наук, доцент кафедры математики и информатики
344003, г. Ростов-на-Дону, пл. Гагарина, 1
Нелли Борисовна Руденко, кандидат технических наук, доцент, доцент кафедры математики и биоинформатики
347740, г. Зерноград, ул. Ленина, 19
Наталья Николаевна Грачева, кандидат технических наук, доцент кафедры математики и биоинформатики
347740, г. Зерноград, ул. Ленина, 19
Литвинов В.Н., Руденко Н.Б., Грачева Н.Н. Разработка модели параллельно-конвейерного вычислительного процесса для решения системы сеточных уравнений. Advanced Engineering Research (Rostov-on-Don). 2023;23(3):329-339. https://doi.org/10.23947/2687-1653-2023-23-3-329-339
Litvinov V.N., Rudenko N.B., Gracheva N.N. Model of a Parallel-Pipeline Computational Process for Solving a System of Grid Equations. Advanced Engineering Research (Rostov-on-Don). 2023;23(3):329-339. https://doi.org/10.23947/2687-1653-2023-23-3-329-339



ISSN 2687-1653 (онлайн)
Связаться с: Издателем / Редакцией журнала
Издатель: Донской государственный технический университет - ДГТУ, Ростов-на-Дону, Россия - https://donstu.ru/
Главный редактор: доктор технических наук, профессор, проректор Донского государственного технического университета Бескопыльный Алексей Николаевич





































